
Dependent Join
You are looking at an older version of the documentation. The latest version is found here.
When joining a small and large table across multiple data sources. A dependent join is a great strategy to reduce the amount of rows returned from the larger table. Consider the query below:
SQL
SELECT
soh.customerid,
soh.subtotal
FROM
dwh.SalesOrderDetailBig sod
JOIN pgsql_local_data.SalesOrderHeader soh
ON sod.salesorderid = soh.salesorderid
OPTION MAKEDEP dwh.SalesOrderDetailBig
;;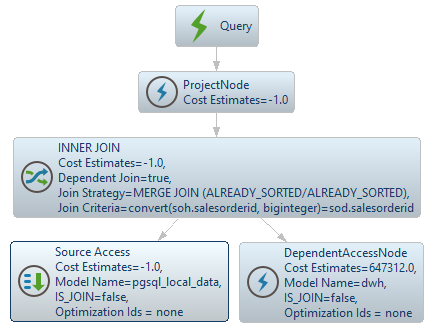
The Data Virtuality Server first retrieves the rows from the smaller table:
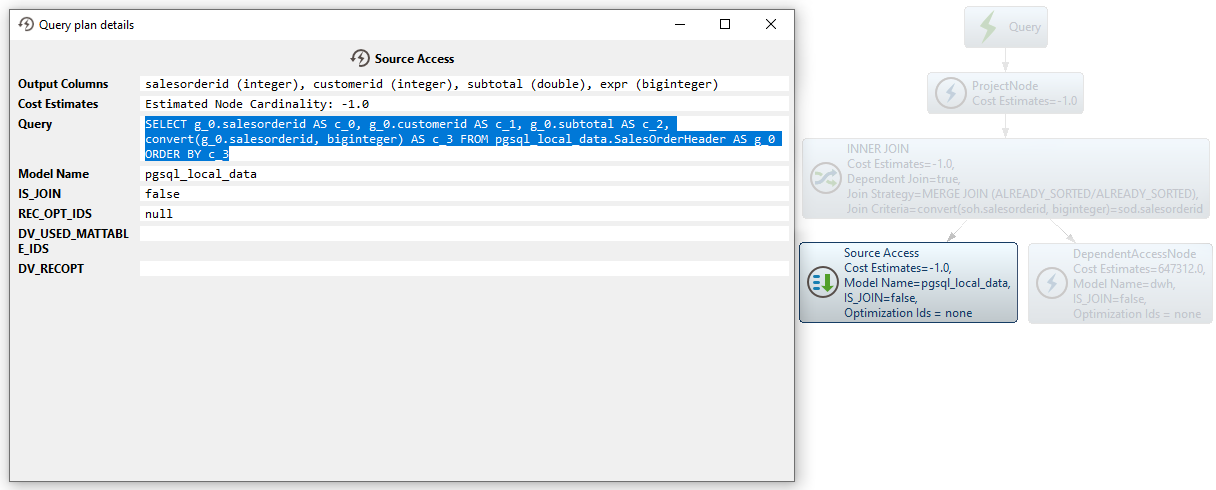
SQL
SELECT g_0.salesorderid AS c_0, g_0.customerid AS c_1, g_0.subtotal AS c_2, convert(g_0.salesorderid, biginteger) AS c_3 FROM pgsql_local_data.SalesOrderHeader AS g_0 ORDER BY c_3Next, the salesorderid values from the smaller table are used to generate a WHERE IN clause to limit the data from the larger table. This can greatly reduce the memory and CPU usage required to process the query (note the 
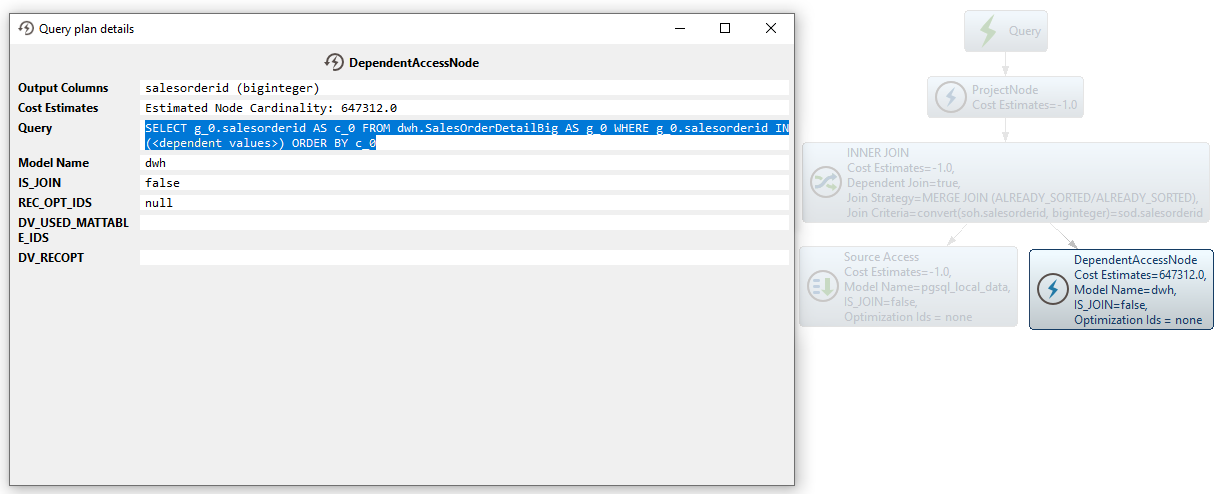
SQL
SELECT g_0.salesorderid AS c_0 FROM dwh.SalesOrderDetailBig AS g_0 WHERE g_0.salesorderid IN (<dependent values>) ORDER BY c_0Then a merge join is performed to join both result sets:
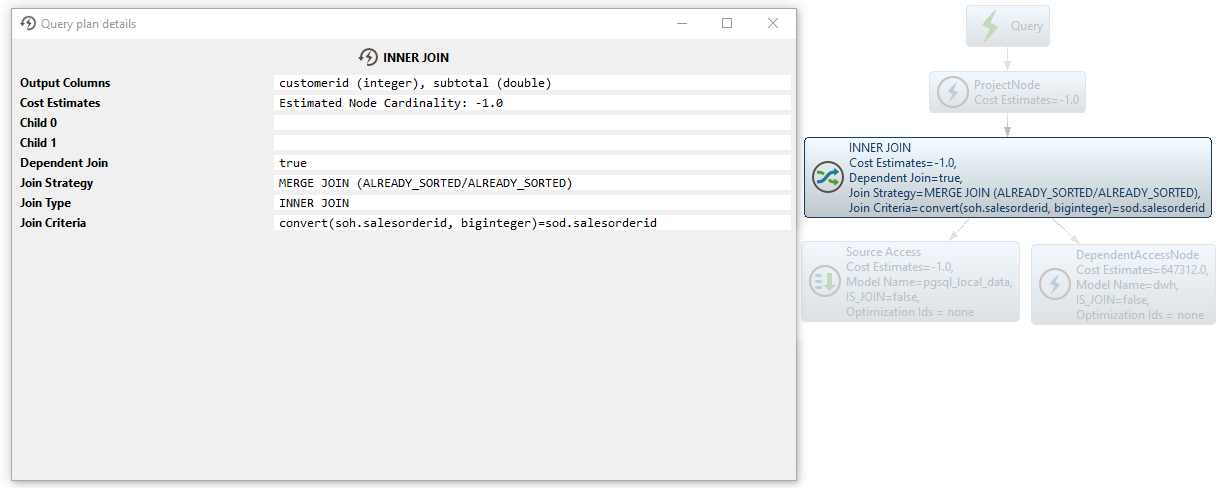
While for large tables the benefits of splitting a query into multiple ones and executing it on one of the sources seem straightforward, for smaller tables, the costs of running multiple queries can be higher than the effects of the parallelism. The exact tradeoff is hard to predict automatically. Because of this, we recommend using dependent joins sparingly and, as discussed in a later chapter, only gathering data source statistics in case some very large tables are present in the joins. A Merge Join is almost always preferable to Dependent Join for smaller tables.