
Incremental Materialization
You are looking at an older version of the documentation. The latest version is found here.
Incremental materialization is more efficient than complete materialization, as it copies only newly added data from the source table to the analytical storage. Here are some cases when it may come in handy:
The source table only gets new entries and no updates/deletes (table with data from customer purchases);
Although the source table is quite large, the amount of rows that has been changed is comparatively small;
You need to keep all records, even when they are deleted from the source.
The tricky thing about incremental materialization is that it requires a column with a reliable timestamp value which can be used to easily determine which rows are new and which are not. For example, this can be a Modified column displaying exactly when a row is changed (newly inserted or updated), or a column providing an autoincremented ID.
In theory, you can use any column as a row check field, but we recommend making sure that its content can reflect changes or new entries. Otherwise, the rows freshly retrieved from the source can be false (missing rows, missing updates, duplicate rows, and so on).
Please note that the main aspect of this materialization is knowledge of time relating to the source's rows. Incremental materialization itself does not use stages for materialized tables. But you can make use of stages by running complete materializations additionally. Each complete materialization will deliver a new stage of the used materialized table. Until the next complete materialization, each incremental job will use the most current stage and not add any more stages. Consequently, if only incremental materialization is used, there will be no stages to fall back to.
When the materialization job runs, the current data of the materialized table is scanned and either the maximum of a specific column is generated or a user-defined expression is calculated.
For our example here, we use timestamps and used-defined expressions.
How It Works
To add a materialization to an optimization in the Data Virtuality Studio, do the following:
- Open the replication job dialogue in the Data Virtuality Studio and go to the optimization menu.
- Click Materialize and then Create materialization job:
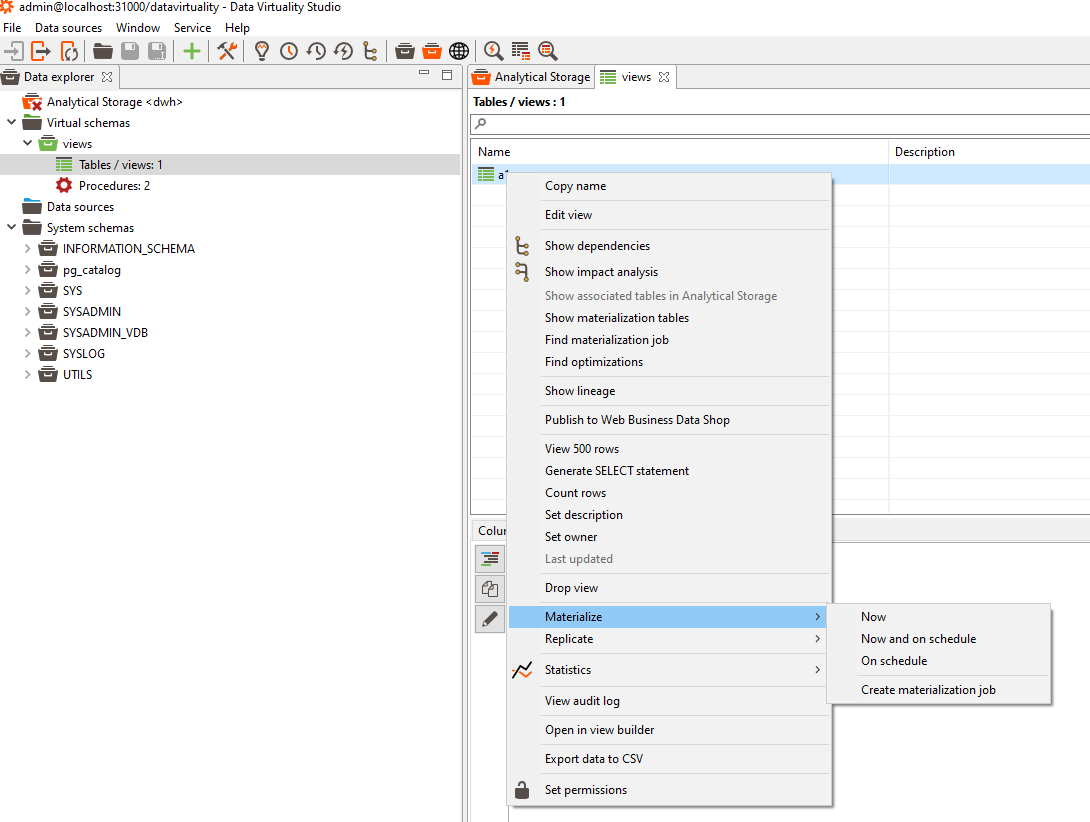
- In the dialogue, select the Incremental tab:
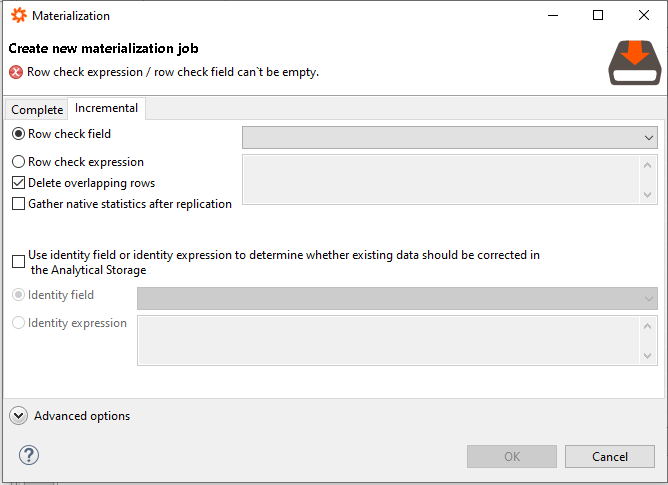
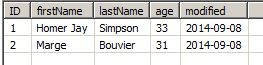
As shown above, the Row check field 'modified' is selected. If the replication runs for the first time, the current source data will be stored in an analytical storage table. This result is independent of any settings, but the second run of the replication job is the one that matters. In our example, the source data consists only of two rows:
Delete Old Data
When there is nothing else provided apart from the Row check field, the next run will query the source for all rows that have modified > 2014-09-08. The value is dynamically calculated from the recent data in the materialized table. If we now consider that the source table gets updates or inserts on the same date, these rows will not be taken into account for the update. If Delete old data is unchecked, only records that have a modified value of greater than or equal to '2014-09-09' will be loaded into the materialized table. This might result in a gap between the analytical storage data and the actual data in the source. Assuming that three more entries have been made in the source, the next job runs will yield the following tables, depending on Delete old data:
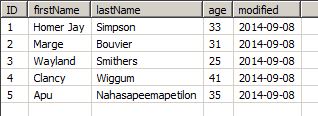
There can be a major difference between replication jobs with or without the Delete old data setting. This greatly depends on the data type in the Row check field and the times when the job is run. Best practice is to use a column that provides a timestamp data type (date and time) and to activate the setting. It will also allow updating rows from the same date (or timestamp).
Here are the underlying statements to show the concept:
Without Delete old data and modified as Row check field
SELECT ... INTO ... FROM ... WHERE source.modified > (SELECT MAX(modified) FROM <materializedTable>)With Delete old data and modified as Row check field
SELECT ... INTO ... FROM ... WHERE source.modified >= (SELECT MAX(modified) FROM <materializedTable>)If new rows appear with a proper later date, the entry will always be loaded into the local table. This is no problem as long as the records are truly new and not updated versions of existing ones:
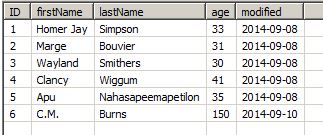
Identity Columns
The notion behind identity columns is quite simple. If the source table only gets new records and never updates on the existing ones, you can be sure that you will never have any duplicate entries in your materialized table. But what if there is an update on an existing row which will also increase the value of the date (or timestamp)? Then the updated row will be retrieved from the source and the Data Virtuality Server needs to know how to proceed.
If no identity field is used, the updated row will be inserted into the local table as an additional row to the ones existing and you might end up with duplicates.
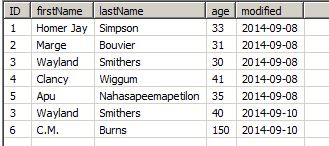
Wayland Smithers aged 10 years in 2 days and the table presents you now with the old and the updated row. You can avoid these duplicates by selecting an identity field (or providing an identity expression). With this option, the Data Virtuality Server scans the new rows and checks, if there are any rows received from the source which are merely updates of existing local rows and performs the update. The example used the column 'ID' as identity field.
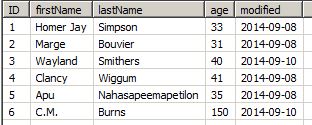
As shown above, the record exists only once but with the most current values and there are no duplicates.
You have to carefully scrutinize the structure of the source object in order to determine whether or not to use the Delete old data and Identity settings.
Since the incremental update can only check for specific new rows from the source, records that are deleted in the source will remain in the materialized table. It is not possible with this approach to determine which records are deleted.
Overview of Incremental Materialization Settings
To view the full table, click the expand button in its top right corner
Setting | Purpose | What happens if not used | What happens if used |
|---|---|---|---|
| Row check field (Row check expression) | Determine which rows to retrieve from the source | N/A (this setting is mandatory) | All records in the source with a value below the maximum of this column in the local table will be ignored |
| Delete old data | Specifies whether new rows will be retrieved with > MAX(Row check field) or with >= MAX (Row check field) | Can lead to missing rows from the source | Will never miss new rows and might even update ones with the same value in the Row check field |
| Identity field (Identity expression) | Specifies how to detect duplicates | No detection for duplicates. A record can occur several times (one additional row per update) | Duplicates are detected by column value (or expression), and the old rows will be updated with the new values |