
Batch Replication
Batch replication is a type of replication which is easier to implement than incremental replication (but less flexible) and more powerful than complete replication. It also differs from both in several ways:
Old rows can be kept even if deleted from the source;
Updates can be performed on current rows, and inserted rows will be added;
No timestamp column is required to get new rows because all rows will be retrieved from the source;
You can decide whether or not to allow duplicates in case of updates on rows;
You can also decide how to name the analytical storage table, and there will be no different stages to distinguish, just one table containing the data.
The main concept of batch replication is one fixed table residing in the analytical storage, updated whenever the replication job runs. Unlike complete replication, the user provides the name for this table, and there are no stages. This offers transparency because there is always one stage of the table, but comes with a risk in case of accidental data loss (by dropping, for example) once the table is lost. The table is created and filled with data at the first run.
How It Works
To set up batch replication in the Web UI:
Open the replication job dialogue in the Web UI and go to the Batch tab.
Indicate the name of the target data source and target table.
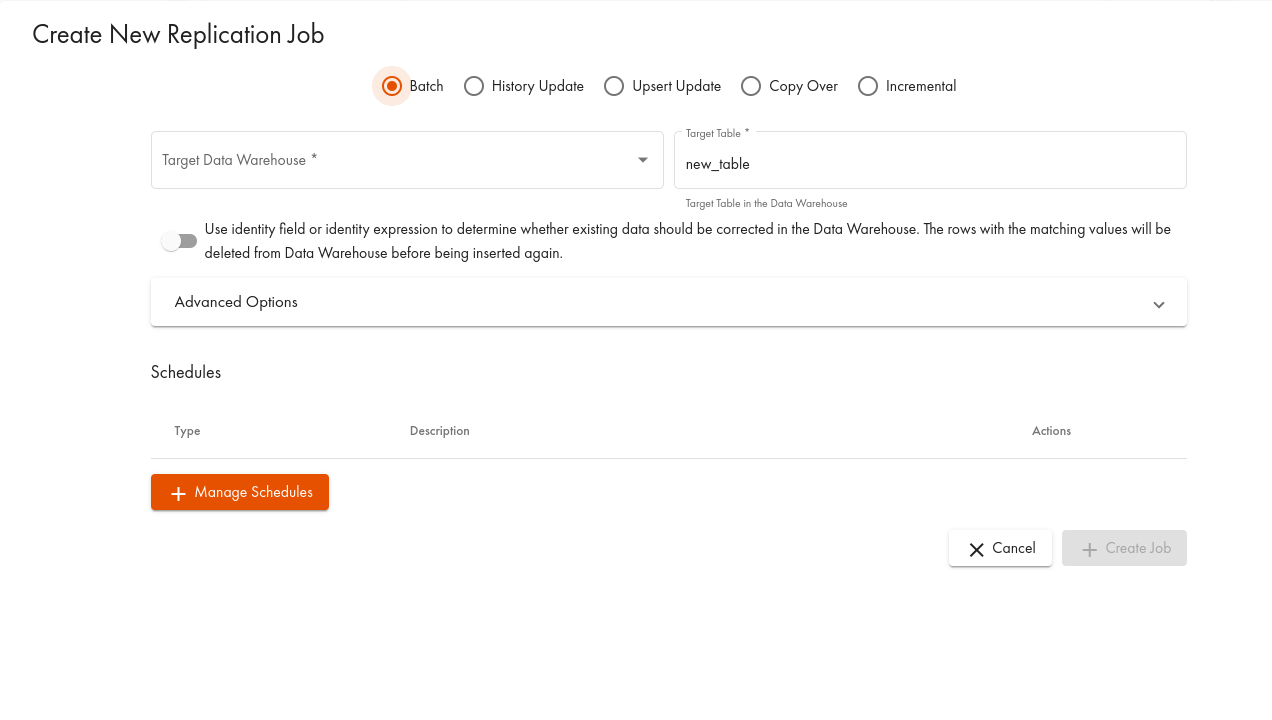
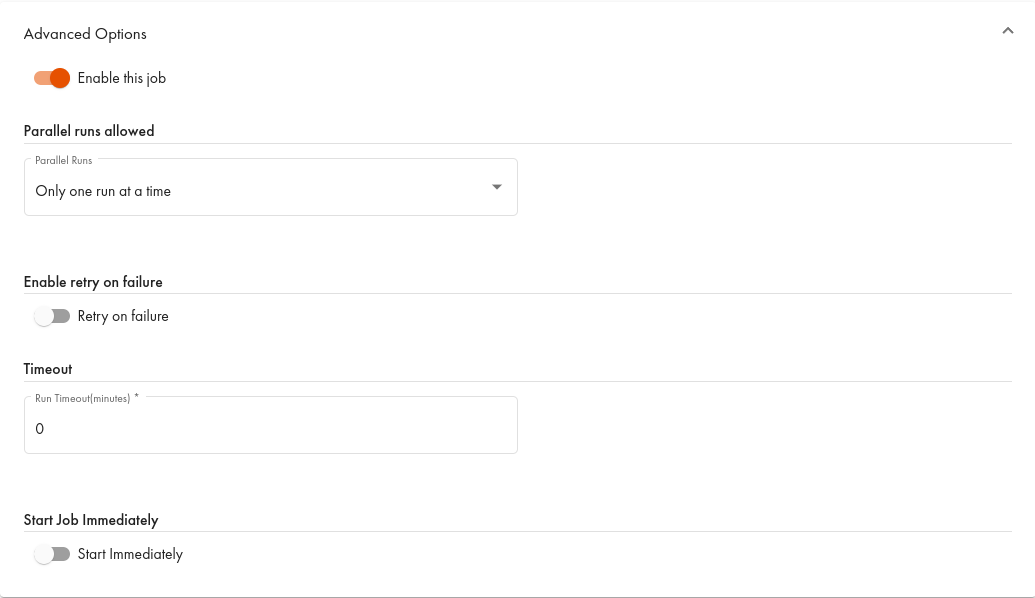
As the dialogue suggests, setting up the batch replication is quite simple. The only mandatory information is the name of the target data source and the target table. It will be created at the first run and filled with data from the source. Although the screenshot shows the identity setting activated, we will first glance at the results without this option and after several replications whilst the source undergoes some updates.
Examples
1. Without identity field (or identity expression):
The first run of the job yields the following data:
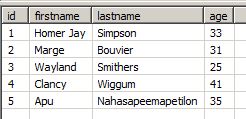
When there is a new entry in the source, and we rerun the replication, the whole result set is added to the current table, and we have duplicates for all records that are already in our table, even if they did not change:
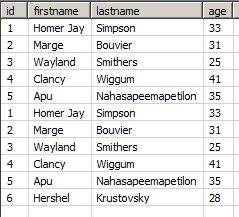
We can go on for all other replication runs, including the update on Clancy Wiggum (new age: 50):
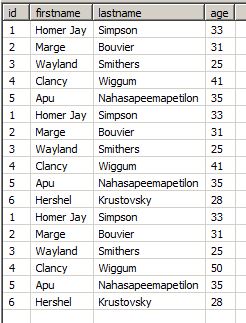
Or after removing the entry for Marge Bouvier:
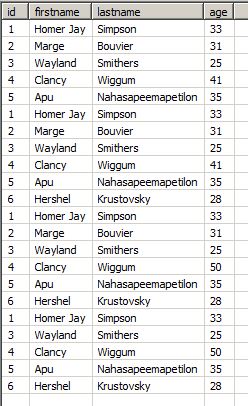
It is evident that this setup should only be used when the replication job runs will always return updates or new rows, but no 'old' data. Otherwise, there will be a lot of ambiguity within the table, and it is questionable whether reliable queries can be made against it.
2. Using the identity field (or identity expression)
To avoid such duplicates, we can decide which column is regarded as an identity field and whose values can never occur more than once within the table. This keeps a clear record of the changes, and new rows will also be added.
Please note that the batch replication now works a bit differently. At first, the whole table is retrieved from the source with the complete content. The second step is to delete all entries that violate the identity requirement when all retrieved data is added from the current analytical storage table. This ensures that all retrieved data can be added to the current table, and there will be no duplicates. Also, updating the existing records will work since the old ones have been deleted beforehand. If the potentially duplicate entries are deleted from the retrieved data, the analytical storage table will store old rows rather than the updates.
Here is how the data from our first test run looks:
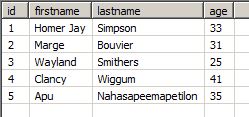
Insert operations will not lead to duplicates after the next run, but a new entry will be added to the table:
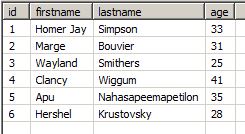
The same is true for an update of Clancy Wiggum's age:
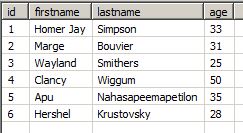
The delete operation will have no impact because how updates are performed is closely related to incremental replication. If a record is deleted from the source, it will be kept in the analytical storage table. If you need to keep detailed track of data changes, consider History Update.
See Also
A short guide on data replication types and use cases. Batch Replication for a blog post on batch replication and its use cases