
Incremental Replication
Incremental replication is more efficient in some cases, as it copies only newly added data from the source table to the analytical storage. Here are some cases when it may come in handy:
The source table only gets new entries and updates, but no deletes (for example, a table with data from customer purchases);
Although the source table is quite large, the amount of rows that have been changed is comparatively small;
You need to keep all records, even when they are deleted from the source.
The tricky thing about incremental replication is that it requires a column with a reliable timestamp value which can be used to easily determine which rows are new or updated and which are not. For example, this can be a Modified column displaying exactly when a row is changed (newly inserted or updated), or a column providing an autoincremented ID (only for inserts, not updates).
In theory, you can use any column as a row check field, but we recommend making sure that its content can reflect changes or new entries. Otherwise, the rows freshly retrieved from the source can be false (missing rows, missing updates, duplicate rows, and so on).
For our example here, we use timestamps and used-defined expressions.
How It Works
To add a replication job in the Web UI, do the following:
Open the replication job dialogue in the Web UI and go to the optimization menu.
Click Create New Job and then Create Replication Job:
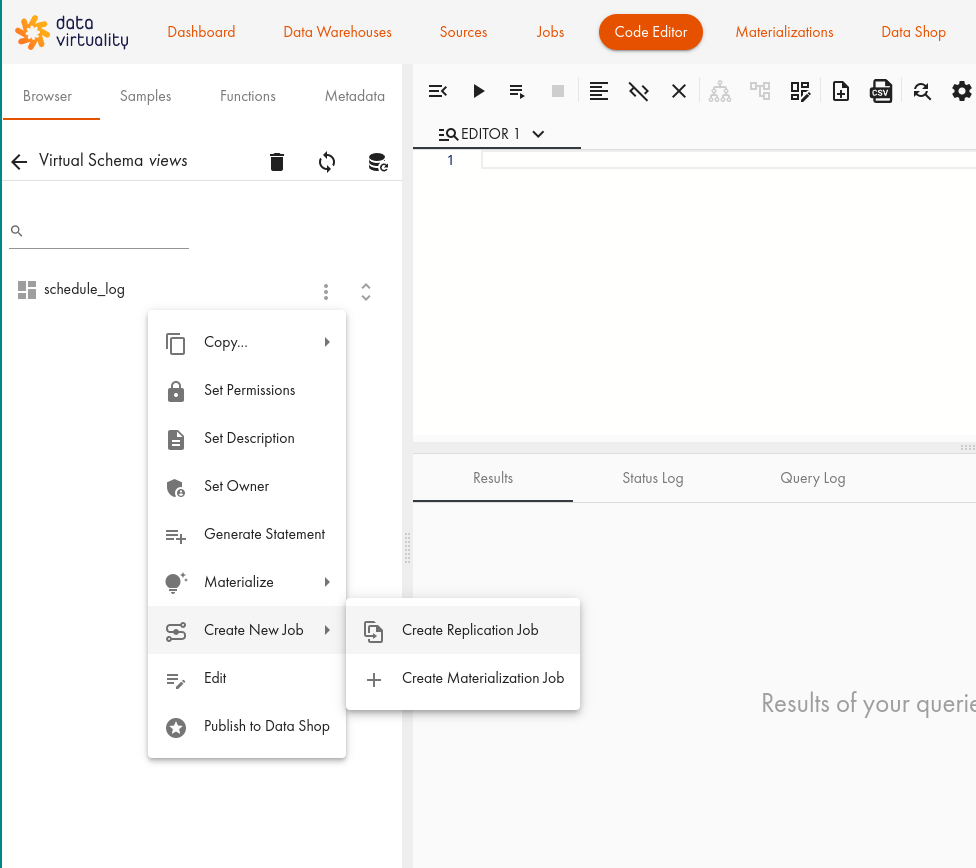
In the dialogue, select the Incremental tab:
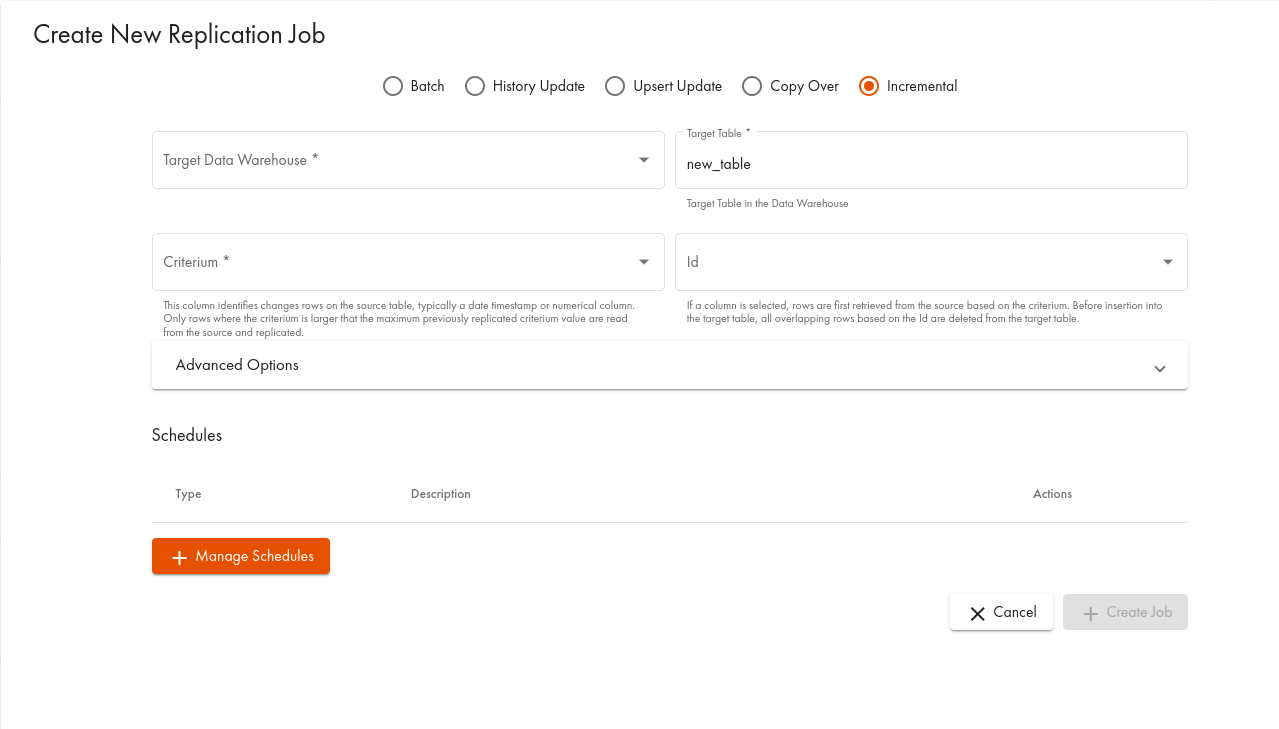
Here is an explanation for the fields:
Parameter | Description |
|---|---|
Target data source | Fully-qualified name of the source. Must be an existing table; mandatory |
Target table | Fully-qualified name of the target; mandatory |
Criterium | Criterium column name. This is the column name of the incremental field. Usually, this will be an integer/long or timestamp column. The procedure calculates the maximum value of this field and inserts/updates the records from the source table with a value larger than already existing in the target table; mandatory |
Id | ID column name to handle updated rows. If this parameter is specified, existing rows with a criterium larger than the maximum will be deleted and re-inserted to handle modified rows. If this parameter is omitted, all rows with a larger criterium will be inserted into the target table. If the key column exists in the source table, but was not specified, the result table will contain multiple entries for each key |
See Also
incrementalReplication - a dedicated utility procedure for performing an incremental replication of the source into the target defined by the id and criterium columns
A short guide on data replication types and use cases. Incremental and Upsert Replication - a post in the CData Virtuality blog explaining incremental replication and its use cases