
Introduction to CData Virtuality Server
CData Virtuality Server at a Glance
The CData Virtuality Server offers a simple yet powerful tool that enables you to combine multiple heterogeneous data sources via one unified platform. Thanks to an entirely dynamic approach, automated detection of schemas for the different data sources enables you to quickly build an analytical storage without the involvement of time-consuming ETL processes. Using well-known SQL constructs through a virtual relational layer, you can perform any query involving several data sources. As the CData Virtuality Server is only a layer between your data sources and your analytical storage, you can choose from various popular providers to host the analytical storage and benefit from state-of-the-art in-memory techniques that allow for the highest performance when querying live data instead of locally hosted content. Popular business Intelligence tools such as Tableau, QlikView, and many more can directly connect to the CData Virtuality Server since it provides both JDBC and ODBC interfaces. This diagram illustrates CData Virtuality's (of which the Server is an integral part) role within your BI-focused environment:
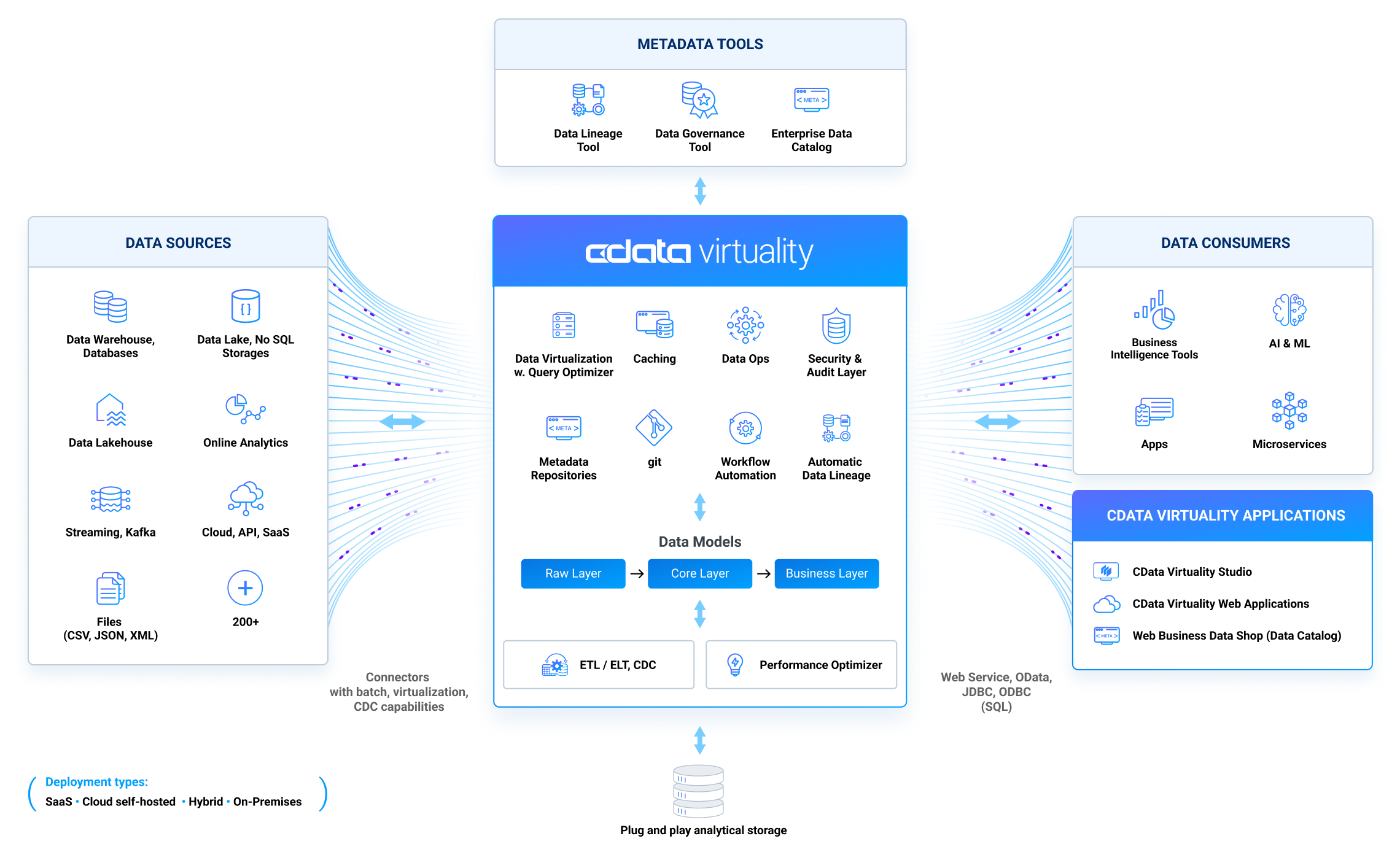
Different Data Sources - No ETL
The strength of the CData Virtuality Server lies not only in the possibility of creating an analytical storage but, much more, in freeing the user of ETL processes. This unified data platform can add and use all kinds of data sources. All data sources you want to connect to can be added via a simple wizard that only requires the mandatory information. Afterward, the Server detects the data source's structure and presents it as a virtual relational layer. This comes in handy, especially when you have your data hosted in a non-relational way (the most popular examples are MongoDB, Salesforce, Google AdWords, and Google Analytics). As the CData Virtuality Server automatically detects the structure of data sources and presents the data in the relational model, you can start immediately. The omission of ETL allows querying live data instantly without getting it into the analytical storage first. State-of-the-art in-memory techniques give highly performant results. Therefore, the CData Virtuality Server offers an intuitive platform to perform business reporting easily and cost-effectively with live data.
See the complete list of data sources supported by CData Virtuality here.
Analytical Storage Hosting
Analytical storage is a special database where CData Virtuality can place the materializations and automatically optimize them by creating indexes on them if needed and allowed by the type of underlying database. Utilizing analytical storage can drastically improve query performance.
The other major feature of the CData Virtuality Server is providing a means for dynamically building analytical storage. Using the relational layer that leaves out the ETL processing leverages the approach to a more dynamic level. You can choose from a wide range of providers to host your analytical storage. You can create personal views that provide you with an option to have the definition of repeating queries quickly at hand. The views are also a good alternative to storing only the important data in the analytical storage instead of everything a data source offers. Of course, you can still decide whether you want to use live data from a source or your locally stored data when executing queries in a very granular way.
See the complete list of analytical storage providers supported by CData Virtuality here.
Optimizations
Throughout your work with the data brought to you from the data sources, you might want to be flexible in terms of how current the information shall be. The technology behind the CData Virtuality Server lets you freely decide which data you want to store in the local analytical storage and which is to be obtained live from the source at the running time of a query. Materialization, the process of getting the local copies of the desired data, can be used for entire tables and specific created views. Additionally, the CData Virtuality Server keeps track of the usage frequency of tables, views, and often used joins and aggregations. Using these statistics, the CData Virtuality Server provides a graphical visualization of these frequencies and advises which ones should be stored in the analytical storage to optimize the query performance. It also suggests which columns should be indexed depending on their appearance in queries. If you prefer to use live data for specific queries from specific tables, the most up-to-date in-memory techniques guarantee the minimum running time when the CData Virtuality Server performs these operations. Live data, analytical storage hosted data, or a combination of both is possible.
Replications
When using analytical storage technologies, you need to update your local content regularly. Schedule-based replications help to perform updates on the analytical storage data. There are different types of replications: from complete replication, which gets you a local one-to-one copy, to history update that lets you keep track of all foreign data and their changes over time. The latter concept is also known as slowly changing dimensions and can play an important role in some business reports that rely on data that changed or which might have even been deleted by now. A whole range of types of schedules gives you the granularity you need. Schedules can be simple for one-time runs or regular intervals as well as very precise cron jobs or even depending on preceding schedules.
SQL and Business Intelligence
As the CData Virtuality Server is to be understood as an intermediate layer that makes different types of data sources accessible via virtual relational schemas, it is very important to gather information from these different sources easily. Hence, the CData Virtuality Server provides common SQL constructs for this task. The software allows everything from simple SELECT statements to own procedures with dynamic SQL. Thanks to this, you do not have to learn an extra language, and all typical Business Intelligence tools and frontends can build reports based on the CData Virtuality Server. It is also possible to manage the whole CData Virtuality Server via predefined stored procedures. The provided JDBC and ODBC support offers a large set of tools for reporting tasks and gathering business insights.