
Upsert Update
The upsert procedure is intended to provide an easy way to replicate a source table in a table stored in the analytical storage. It is a more sophisticated approach than complete and incremental replication because it can perform UPDATE operations on existing rows and INSERT operations on new ones. Unlike history update, there will never be more than one entry for a row with a distinct set of values for key columns. Additional timestamp columns, like the ones that automatically come with history update, will not be created.
Parameters
To view the full table, click the expand button in its top right corner
Parameter | Type | Description |
|---|---|---|
| string | Target table (analytical storage/data source) the data will be put into. Should have the defined |
| string | Source object (analytical storage/data source) the data will come from |
| object | Key columns to decide whether |
| object | Set of columns which is used to determine which columns will be updated on existing rows |
| boolean | Determines which columns exactly will be updated depending on the value:
|
| string | Determines how to calculate the surrogate key depending on the value:
|
| string | If |
| string | Redshift table creation options ( |
| string | Check field or expression in update statement |
| string | Default value if check field or expression variable is |
Principle of Operation
The procedure retrieves the current data from a given source (source_table) and places the data into the local table (target_table/dwh_table). The decision whether INSERT or UPDATE will be used is based on a set of key columns (keyColumnsArray) that has to be provided. For each of the source rows, the following operation is done:
If there is no row with the same values in the key columns, then an
INSERTwill be done, and the new row will be added to the analytical storage table;Otherwise, the existing row in the analytical storage table will be updated based on the
updateColumnsandinvertUpdateColumnsparameters in the following wayinvertUpdateColumns=FALSE: all the columns fromupdateColumnswill be updated.invertUpdateColumns=TRUE: all columns except the ones inupdateColumnswill be updated.
Please note that columns from keyColumnsArray cannot be enumerated in columnsToCheckArray and they will never be updated, because this would change the row to represent a completely new entity.
How It Works
To set up upsert update:
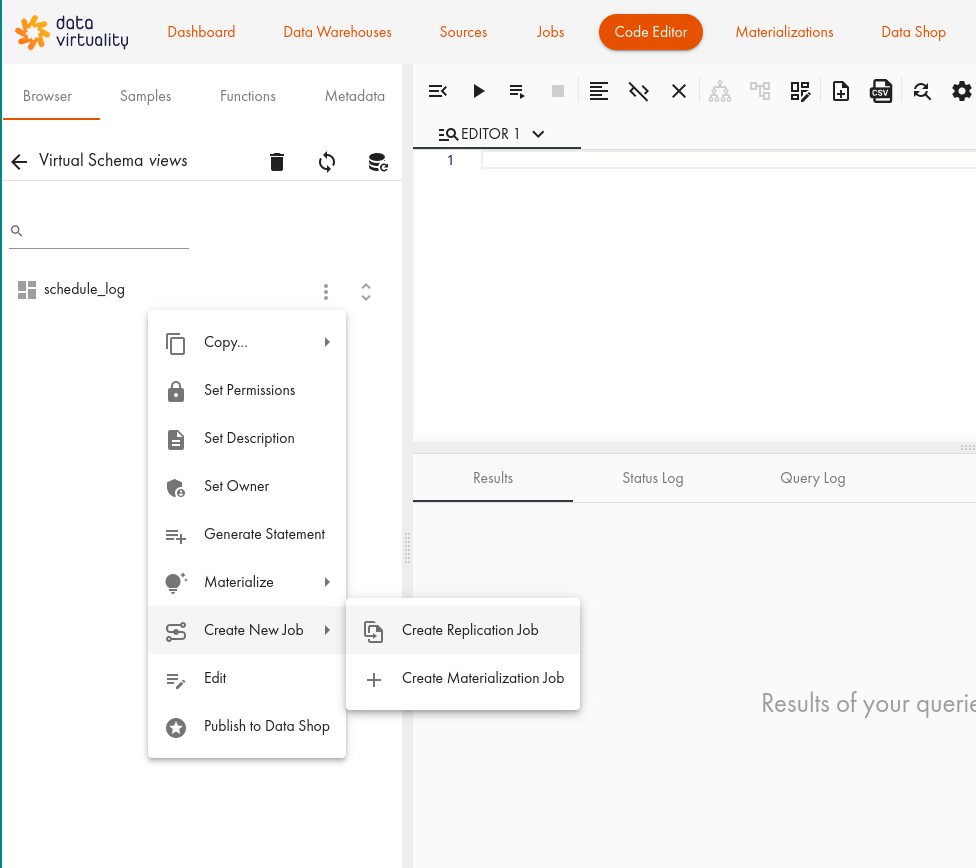
To add a replication job in the Web UI, do the following:
Open the replication job dialogue in the Web UI and go to the optimization menu.
Click Create New Job and then Create Replication Job:
In the dialogue, select the Upsert Update tab:
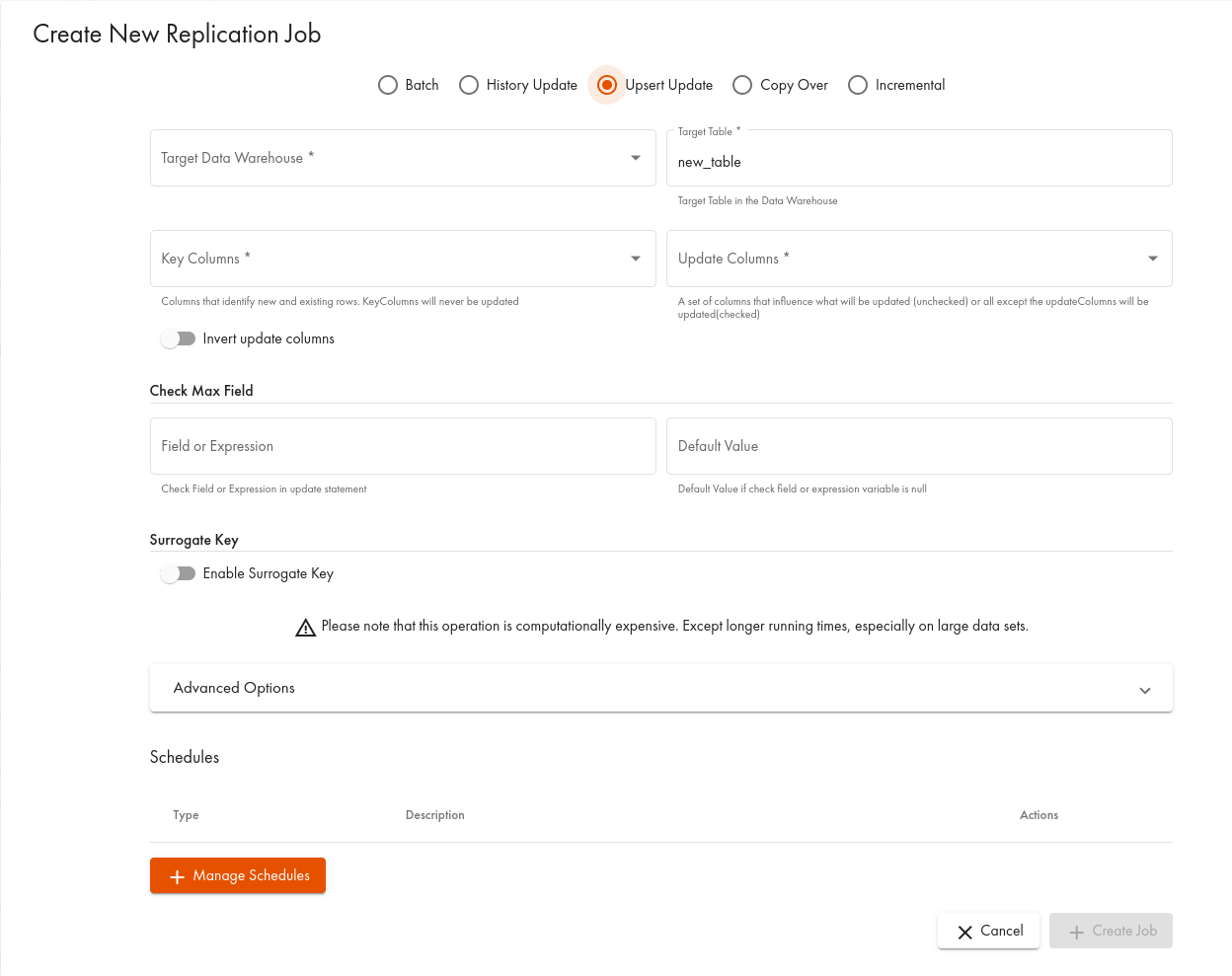
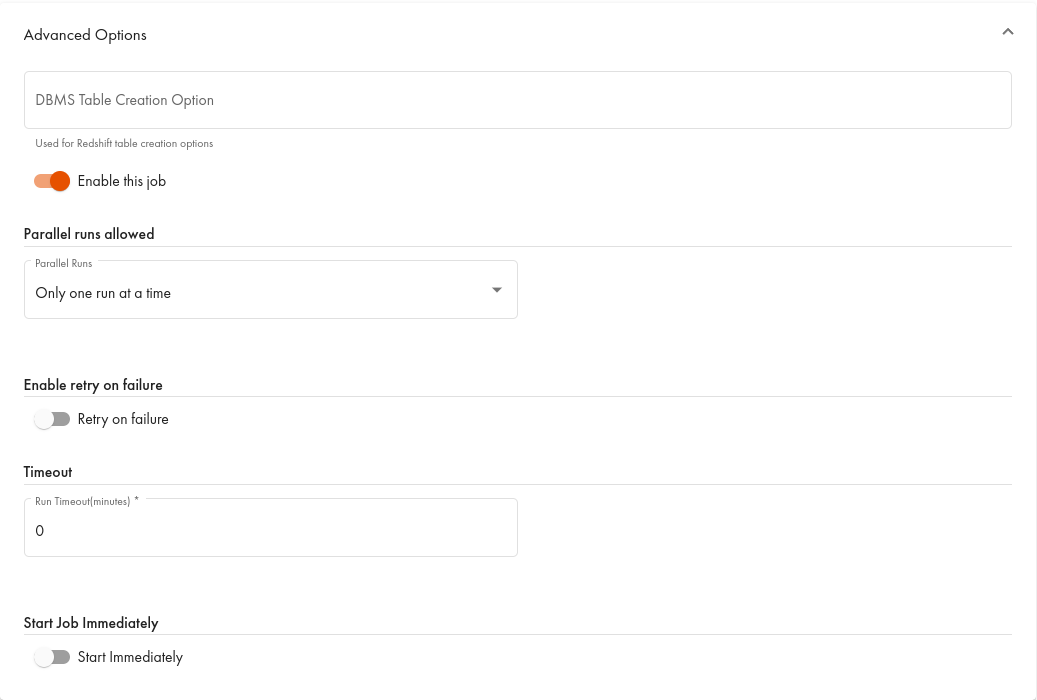
Examples
1. Performing the upsert operation on a source table and 'upserting' these rows into a target table, while updating only the specified columns:
CALL "UTILS.upsert"
(
"target_table" => 'dwh.foo'
, "source_table" => 'ds.bar'
, "keyColumnsArray" => ARRAY('MyID')
, "updateColumns " => ARRAY('col1', col2')
, "invertUpdateColumns " => FALSE
) ;;This call performs the upsert operation on the source table ds.bar and 'upserts' these rows into the table dwh.foo. The MyID column is used to identify which rows have to be inserted into and which ones need to be updated in dwh.foo. If an update is performed, only the col1 and col2 columns will be updated, and the other columns will stay untouched.
2. Performing the upsert operation on a source table and 'upserting' these rows into a target table, while updating all columns except the specified ones:
CALL "UTILS.upsert"
(
"target_table" => 'dwh.foo'
, "source_table" => 'ds.bar'
, "keyColumnsArray" => ARRAY('MyID')
, "updateColumns " => ARRAY('col1', col2')
, "invertUpdateColumns " => TRUE
) ;;This call performs the upsert operation on the source table ds.bar and 'upserts' these rows into the table dwh.foo. The MyID column is used to identify which rows have to be inserted into and which ones need to be updated in dwh.foo. If an update is performed, the MyID, col1, and col2 columns will stay untouched, and all the remaining columns will be updated. This is handy when the set of columns to update is much larger than the set of columns not to update.
In these examples, we used a single column to identify which rows to insert/update in the target table, but it is also possible to use more than one column. The following two examples show how.
3. Performing the upsert operation on a source table and 'upserting' these rows into a target table using several columns to identify which rows to insert/update in the target table, while updating all columns except the specified ones:
CALL "UTILS.upsert"
(
"target_table" => 'dwh.foo'
, "source_table" => 'ds.bar'
, "keyColumnsArray" => ARRAY('MyID', 'SomeID', 'SomeOtherID')
, "updateColumns " => ARRAY('col1', col2')
, "invertUpdateColumns " => TRUE
) ;;This call performs the upsert operation on the source table ds.bar and 'upserts' these rows into the table dwh.foo. The MyID, SomeID, and SomeOtherID columns are used to identify which rows have to be inserted into and which ones need to be updated in dwh.foo. They form a composite key of sorts. If an update is performed, the MyID, SomeID, SomeOtherID, col1, and col2 columns will stay untouched, and all the remaining columns will be updated.
4. Special case: performing the same operations, but inserting a counter into the data source to facilitate adding new rows in the future:
CALL "UTILS.upsert"
(
"target_table" => 'exa.foo'
, "source_table" => 'ds.bar'
, "keyColumnsArray" => ARRAY('id1')
, "updateColumns " => ARRAY('col1', col2')
, "invertUpdateColumns " => TRUE
, "surrogateKeyName" => 'SurrColumn'
, "surrogateKeyType" => 'COUNTER'
, "checkMaxFieldId" => 'id1'
, "defaultValueIfCheckMaxFieldIsNull" => '0'
) ;;This call performs the upsert operation on the source table ds.bar and 'upserts' these rows into the table exa.foo. The id1 column is used to identify which rows have to be inserted into and which ones need to be updated in exa.foo. If an update is performed, the col1 and col2 columns are updated, and the remaining columns will stay untouched. This is useful when the set of columns to update is much larger than the set of columns not to update. The surrogate key with the name SurrColumn will be added to the data source. The value will be the incremental counter of type long. While performing the upsert, a comparison with the maximum value of the id1 column in exa.foo will be performed, and only rows from ds.bar with id1 over the maximum value will be upserted. This is useful if we know that we do not need an update, just adding new rows.
See Also
A short guide on data replication types and use cases. Incremental and Upsert Replication - a post in the CData Virtuality blog explaining Upsert Update and its use cases