
History Update
You are looking at an older version of the documentation. The latest version is found here.
In some cases, we may need to keep track of changes made to data. Complete, incremental, or batch replication will always yield a table which contains all available data; incremental or batch updates may allow keeping 'old' data which is not present in the data source anymore. But generally, changes in data cannot be tracked, and the user is always forced to work with the most current information.
If you need to know when and how the data has been changed, history update is the right replication type to use. There are several ways to implement this type of replication, and on this page, we describe the type used in the Data Virtuality Server.
It is based on performing a kind of versioning on the data records by adding two columns to the analytical storage table where the locally optimized data is stored. These columns, called fromtimestamp and totimestamp, provide information on the period when the given record was the valid version. To use this feature, you need to do the following:
- Select the column of the source object (either table or view) which will be considered the key column. Please remember that the fields should be chosen so that duplicates (entire rows with the same values in all fields) cannot occur.
- Select columns to be tracked for updates when the replication job runs.
How It Works
To set up history update:
To add a replication job in the Web UI, do the following:
Open the replication job dialogue in the Web UI and go to the optimization menu.
Click Create New Job and then Create Replication Job:
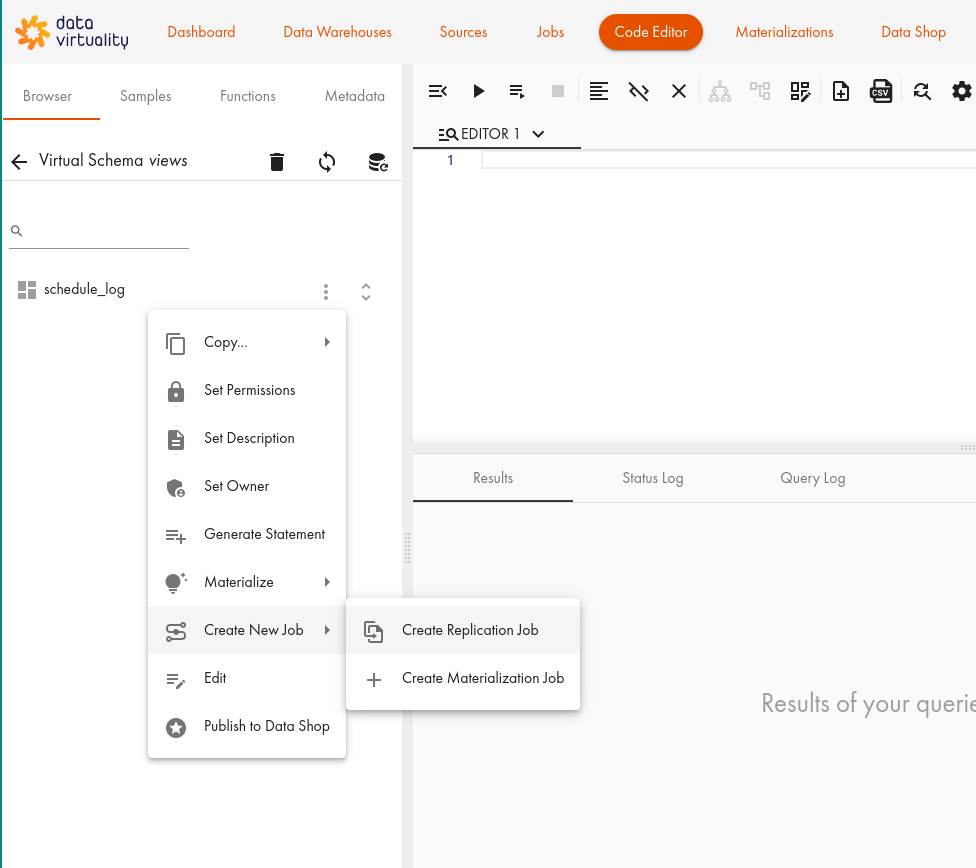
- In the dialogue, select the History Update tab:
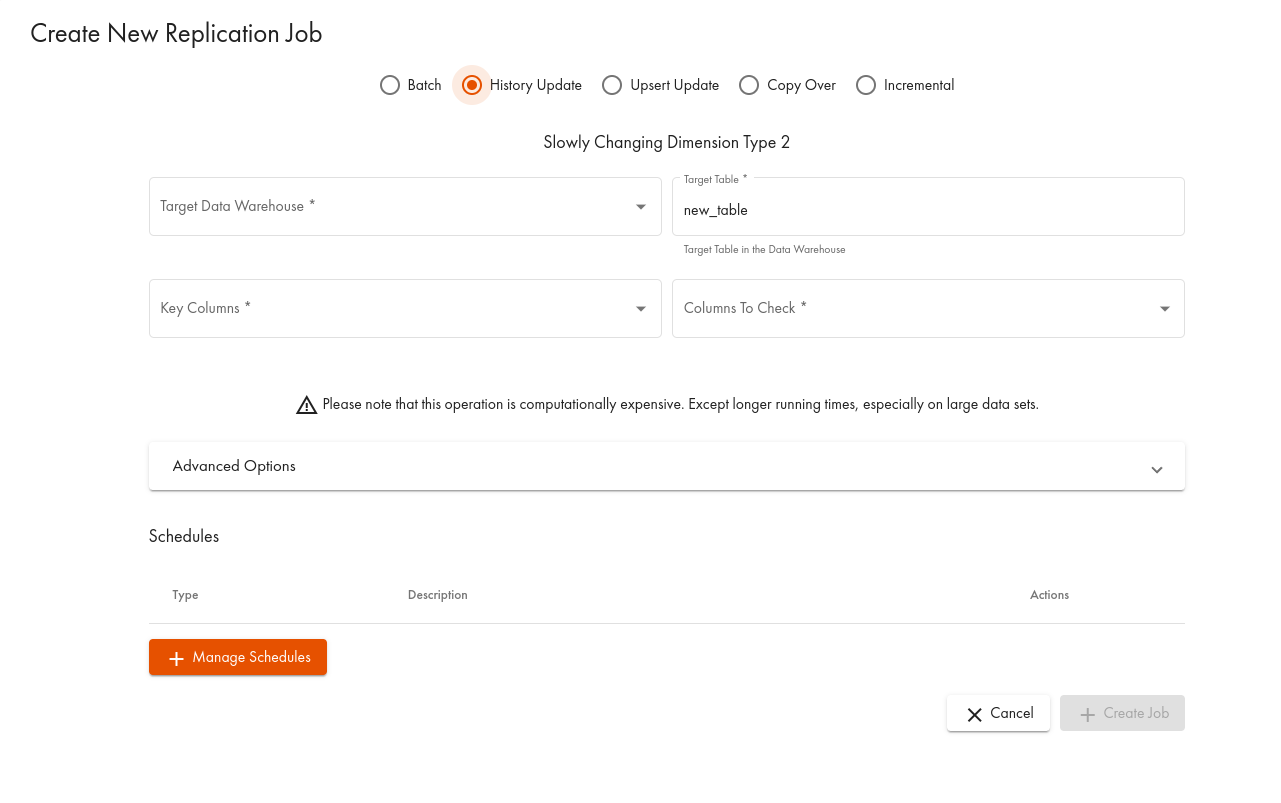
Here is an example: our table is called hEx and uses ID as the key column. We want to check when the age column changes its value for an existing entry. After the replication job has run for the first time (the adding of a schedule or running the job manually is omitted here), there will be one row for each record of the source object with the current timestamp as fromtimestamp and the largest possible timestamp 9999-01-01 00:00:00.0 as totimestamp.
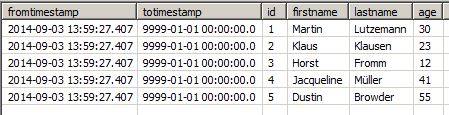
Now, while the usual tasks are being performed, the source changes and the age of Martin Lutzemann changes. The next run of History Update will produce a second entry because we already have a record with the same ID (the key column), but a different age (the column to check). The most current entry for Martin will get a modified totimestamp set to the timestamp of the job run, and the new record will get the same fromtimestamp , and the special totimestamp:
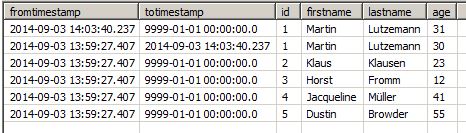
As shown in the screenshot, the timestamp '9999-01-01- 00:00:00.0' indicates this is the most recent one for the records with the same key.
If a column is not monitored by the Data Virtuality Server (i.e. not selected as one of the columns to check), there will be no changes in the local table. Any alteration of these fields will be visible once the tracked fields change values and we have new 'versions' of the respective entries.
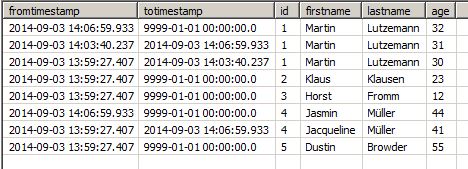
If more changes are done in the source, like Jacqueline changing her name and ageing by three years, the next run will produce new versions of the records. There will be, of course, only one new version of a record, even if all tracked columns changed and there were many.
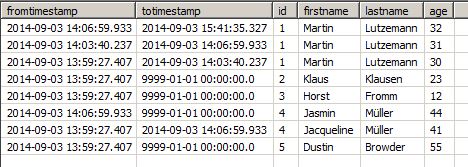
When the deprecated entries are removed from the data source, they will be kept in the local analytical storage table but get stripped of their pseudo-infinite totimestamp and get a proper one. If Martin Lutzemann is removed from the source table, he will remain in the History Update:
See Also
A short guide on data replication types and use cases. History replication - a post in the Data Virtuality blog on history replication