
Git Integration
With the CData Virtuality Server, you can use Git for version control. Currently, our implementation of Git integration supports basic objects: data sources, virtual schemas, views, stored procedures, jobs, schedules, queue handlers, optimizations, recommended indexes, recommended optimization symbols, remarks, users, roles, permissions, data catalog attributes, and objects published to the web business data shops with plans to add more types of objects in the future. To manage Git integration, the CData Virtuality Server has dedicated stored procedures for working with Git which are described in detail here.
Development on a Single Instance
This diagram shows development on a single instance:
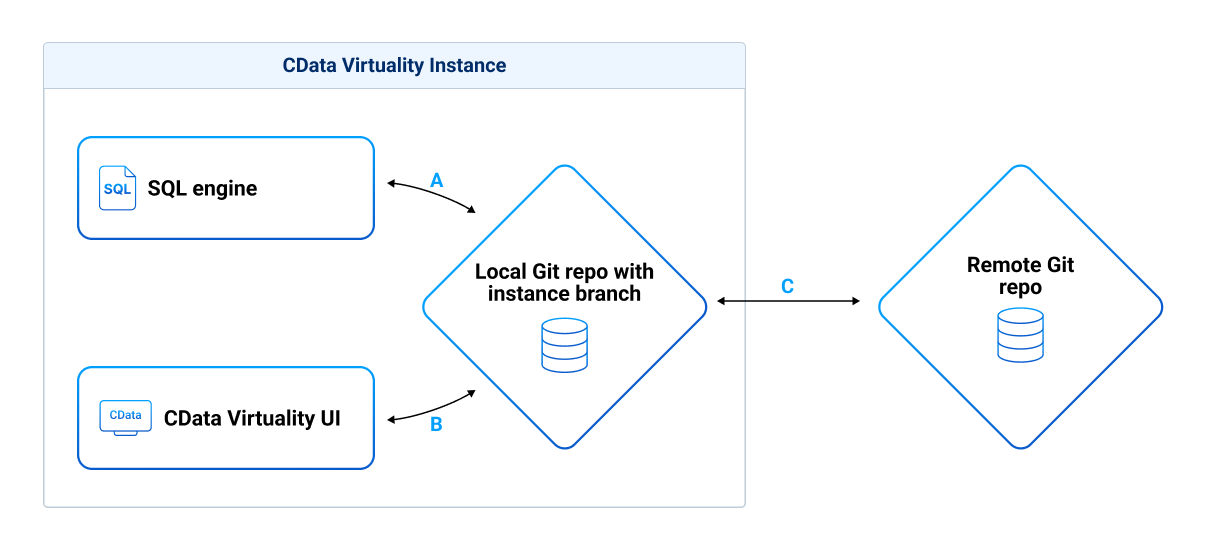
Each instance has one current branch, which is configurable. Multiple instances can also run the same branch.
Outgoing Flow (from SQL Engine over Local to Remote Repository)
All changes done on the SQL engine are automatically “staged'' in the local repository (A).
Changes are pushed to the remote repository manually (using an SQL stored procedure) or automatically/on schedule (C)
Some objects can be generally excluded from commits.
Incoming Flow (from Remote Repository over Local to SQL Engine)
From the remote to the local repository: git pull from the remote repository with a stored procedure (C).
From the local repository to SQL Engine: git deploy with a stored procedure (B) to apply the changes from the repository.
It is possible to check out a different branch onto the instance, which will clean up the instance from the previous branch and completely deploy the new branch.
Deployment Between Instances over the Central Git Repository
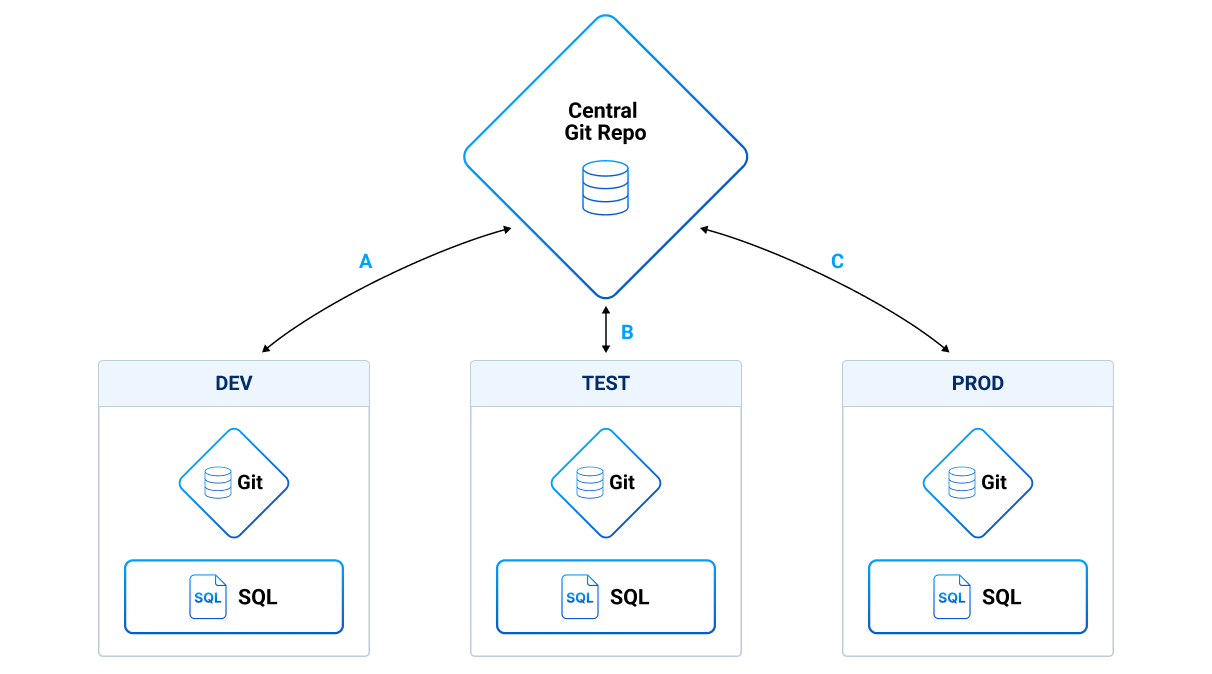
This diagram shows deployment between instances over the central Git repository:
Development
Push from development to the central repository can be done manually or via a scheduled job.
You can merge to the master branch in the central repository or work without the master branch.
The code review process depends on the toolset. For example, with Gitlab you can use a code review process based on merge requests. With Crucible, code review can be based on a set of commits for a JIRA issue.
Deployment on Test/Production
For deployment on test/production, the changes are merged in the relevant branch.
There are two possibilities for updating the test and production environments:
Combination of the gitPull and gitDeploy procedures, i.e., getting the latest changes and deploying them to the SQL engine (this can be done manually or automatically). Only the changed objects are deployed;
Checkout where the new branch is checked out locally on the instance and deployed by the SQL engine, wiping the SQL engine contents before applying the new branch.
For rollback, the individual commit is checked out/deployed (which includes resetting the server beforehand).
Tagging
In git, tags are used to label a specific point in time in a repository's history. The most common usage is to mark a release point (such as "v0.5", "1.0.0", and so on).
You can create a tag at any moment that the git repository is enabled using the gitTag procedure. The tag will be created locally and it is necessary to execute a gitPush to send the local tags to the remote repository (in case one is defined).
Since tags are mostly used to mark releases, one simple way to use it is to call the gitTag procedure when the development of a feature is done, to mark that point in time as a relevant milestone. The most usual development workflows use branches to handle different environments (like test and deploy), but it is possible to tag a specific repository point so that the server can execute a gitCheckout in a specific tag, and deploy its contents to ensure that the server state is the one tagged.