
Pushdown
Pushdown is an optimization technique that moves data processing closer to the data source. For example, imagine a query to a database filtered by a WHERE clause. If no pushdown happens, CData Virtuality will have to read all the data into memory and remove the rows that do not apply to the filter. In contrast, if pushdown happens, the WHERE clause will be applied directly at the RDBMS of the data source, and it will deliver only the rows that apply to the filter. The performance impact here is that less transfer of data and less processing time on CData Virtuality will be needed.
Pushdown is available for functions, criteria, joins, and aggregations. The set of available pushdowns differs across data sources, limited by the driver and translator capabilities.
To identify a pushdown in a query plan, it is generally indicated by a Source Access node:
When double-clicking this node, additional information is displayed, including the query that CData Virtuality was sending to the source (in DV SQL, not the actually executed query on the data source side):
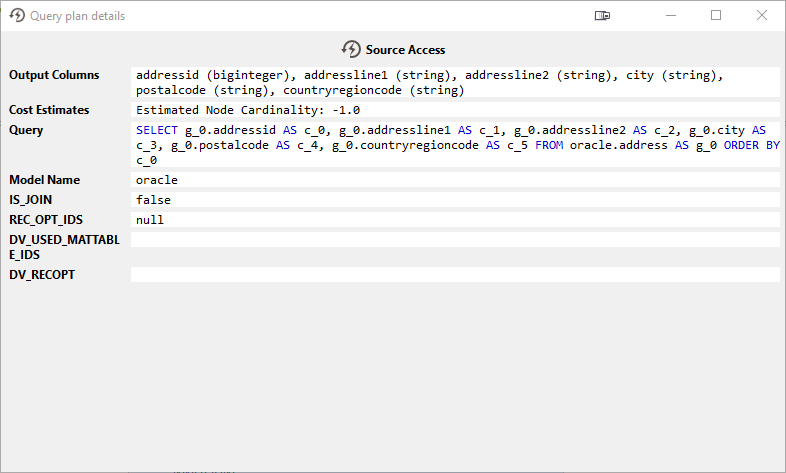
In this example, it can be seen that the result set was sorted, even though there was no sorting in the user query. CData Virtuality automatically applied (and pushed down) the sorting to be able to efficiently join in the next processing step of the processing.
For any data source, the capability of this data source to process pushdown of various operations is defined by the so-called translator inside the CData Virtuality Server. However, many of these capabilities can be overridden, especially for relational databases, using the manual settings documented here.